von Benjamin Altmiks | Juni 24, 2026 | Compliance, Cyber-Sicherheit, Datenschutz, GRC & Informationssicherheit, Machine Learning and AI, News
KI in der Security: Die Frage ist nicht ob, sondern wo man anfängt
Wer ein altes Haus energetisch sanieren will, steht schnell vor einer entscheidenden Frage: Wo fängt man eigentlich an? Tauscht man zuerst die alte Ölheizung gegen eine Wärmepumpe? Oder lässt man besser erst eine Photovoltaikanlage aufs Dach bauen, die den Strom für ebenjene Wärmepumpe liefert? Beides ergibt Sinn, aber welcher der richtige erste Schritt ist, lässt sich ohne entsprechende Expertise oft nur schwer beurteilen.
Bei großen und mittelständischen Unternehmen sieht es gerade sehr ähnlich aus. KI? Ja gerne. Aber wo beginnen? Genau diese Unsicherheit beobachte ich seit längerem auch im Security-Bereich. Der naheliegende Einstieg ist meist ein vertrautes, alltägliches Thema. Viele lassen sich von einer KI zum Beispiel einfach lange Logfiles oder Reports zusammenfassen und auswerten. Und wenn ich der KI ohnehin schon solche Berichte vorlege, warum reiche ich ihr dann nicht gleich mehr Material, etwa den Source Code oder die Netzwerkinfrastruktur, und lasse beides direkt mitprüfen?
Schwierig ist dabei selten die Frage, ob KI hilft. Schwierig ist die Frage, wo man anfängt, ohne sich zu verzetteln.
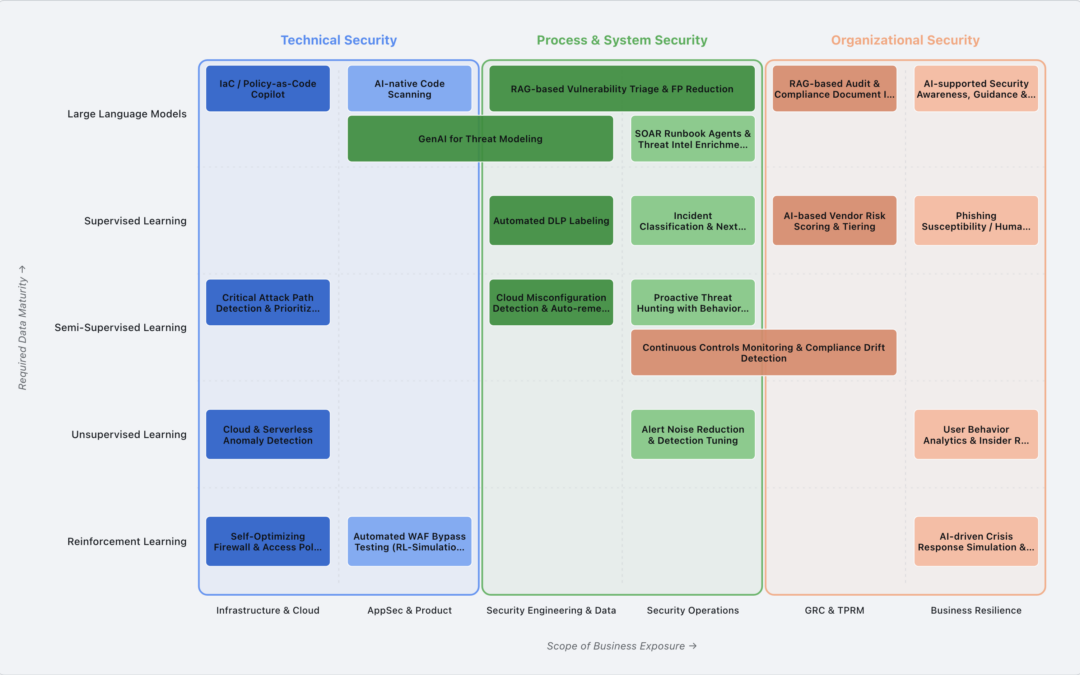
Eine Karte, um sich zu orientieren
Aus genau diesem Grund haben wir den AI Security Landscape gebaut: eine offene Übersicht, die konkrete KI-Anwendungsfälle in der Cyber Security sortiert. Auf der einen Achse stehen die Security-Abteilungen, von Infrastruktur und AppSec über Security Operations bis hin zu GRC und Business Resilience. Auf der anderen Achse steht der jeweils passende Machine-Learning-Ansatz, von unüberwachtem Lernen bis zu Large Language Models.
Der wichtigste Gedanke dahinter: Ein LLM ist nicht immer die beste Wahl. Für viele Aufgaben passt ein klassischer ML-Ansatz schlicht besser, ist robuster und braucht weniger Aufsicht. Die Karte macht das sichtbar und hilft Teams zu erkennen, welcher Einstieg zu ihrer Datenlage und ihrem Reifegrad passt.
Ein Beispiel: der Weg zur KI-gestützten Code-Analyse
Nehmen wir ein Unternehmen, das künftig seine Code-Analysen von KI unterstützen lassen möchte. Dass LLMs dazu in der Lage sind, wurde zuletzt eindrucksvoll sichtbar, als ein Modell einen Bug in kritischer Software fand, der zuvor 27 Jahre lang von Sicherheitsexperten unentdeckt geblieben war. Im Alltag der Softwareentwicklung können LLMs auf dieselbe Weise Qualität und Sicherheit spürbar verbessern.
Nur: Ein LLM ohne Zusatzinformationen einfach blind über den Code laufen zu lassen, ist selten der beste Ansatz. Genau hier setzt der AI Security Landscape an. Er zeigt, dass ein vorgelagertes Threat Modeling dem Scanner wertvollen Kontext liefert. Welche Komponenten und Klassen sind besonders kritisch? Wie hängen die Teile zusammen? Mit diesen Antworten weiß die KI, worauf sie zuerst schauen muss, statt flach über die gesamte Codebasis zu scannen.
Das Schöne daran: Auch das Threat Modeling selbst lässt sich von KI vorbereiten. Wie mithilfe des Model Context Protocol (MCP) künftig automatisiert Threat Models erstellt werden können, ist ebenfalls Teil des AI Security Landscape. Damit wird ein KI-gestütztes Threat Modeling oft zum besseren Startpunkt für die erste KI-Umsetzung im Unternehmen, weil es allen folgenden Schritten eine solide Grundlage gibt.
Wenn die Grundlagen schon stehen
Und wenn ein Unternehmen bereits erfolgreich Threat Modeling betreibt und darauf aufbauend ein LLM zur Schwachstellen-Identifikation im Source Code nutzt? Dann hört der AI Security Landscape nicht auf. Er zeigt, welche Ansätze sich parallel oder anschließend lohnen.
Ein gutes Beispiel ist die RAG-based Vulnerability Triage & FP Reduction. Hier laufen die verschiedenen Informationsquellen zusammen, das Threat Model, die Scan-Ergebnisse und ergänzende Kontexte wie Architekturbeschreibungen. Sie werden strukturiert in eine Vektordatenbank überführt, also eine Art zentrale Wissensplattform, auf die ein LLM gezielt zugreifen kann. Auf dieser Basis lässt sich jede gefundene Schwachstelle fundiert bewerten. Das Modell kann mit dem vollen Kontext deutlich verlässlicher einschätzen, was ein echter Befund ist, was vermutlich ein False Positive bleibt und ob eine Schwachstelle überhaupt erreichbar ist.
Aus einem einzelnen Werkzeug wird so Schritt für Schritt eine zusammenhängende Kette, in der jeder Baustein den nächsten besser macht. Genau das ist der Gedanke hinter der Karte: nicht überall gleichzeitig anfangen, sondern dort, wo der erste Schritt den größten Hebel für alle weiteren hat.
Mitmachen erwünscht
Der AI Security Landscape ist ein offenes Projekt. Er lebt davon, dass Praktikerinnen und Praktiker ihre Erfahrungen einbringen, neue Use Cases ergänzen und bestehende schärfen. Wer einen Anwendungsfall vermisst oder aus der eigenen Praxis etwas beitragen kann, ist herzlich eingeladen, mitzuwirken.
Einen Topic beizutragen ist bewusst einfach gehalten: eine Markdown-Datei kopieren, ausfüllen, Pull Request öffnen. Den Rest prüft die Pipeline automatisch. Jeder Beitrag macht die Karte ein Stück nützlicher für alle, die gerade vor derselben Frage stehen: KI in der Security, ja gerne, aber wo anfangen?

von Michael Helwig | Jan. 4, 2026 | Compliance, Cyber-Sicherheit, GRC & Informationssicherheit, Machine Learning and AI, News
by Michael Helwig
Predictions are fun, but they rarely turn out the way we expect. So, rather than speculating about what might happen, let’s examine what shaped AppSec and the Cybersecurity industry in 2025 and what is likely to keep us busy in 2026. This is my personal point of view, which is strongly influenced by my focus on application security and the associated compliance challenges.
Architecture Complexity: Cloud, APIs, LLMs and Agents
The complexity of modern application environments increased again in 2025. With cloud-native services, expanding API ecosystems and AI embedded in everything from internal tools to customer-facing systems, it has become increasingly challenging to keep pace. We try to develop a better understanding of worthwhile use cases and AI integrations while we continue to explore the ‚alien tool‘ (Andrej Karpathy) of LLM technology, still wondering whether Prompt Injection is a feature or a vulnerability. But autonomous agents and the MCP stack are already introducing additional layers of automation and security concerns. Developers, with the help of AI, are moving fast and occasionally break things. Unfortunately, security practices have not fully adapted and remain an afterthought. Efforts to retrofit ’security by design‘ into these fast-moving environments are ongoing. Managing security across multi-cloud and API-centric architectures, with the added complexity of AI, and the access to backend systems and large datasets it provides, is a significant challenge, even for well known market players. In 2026, we can expect this complexity to persist. Perhaps focusing on better visibility, not blindly trusting every new technology and improving integration and communication between architecture and security will help tackle it, until tools improve and security processes mature. Also we should not forget to keep in mind all our basic security practices (after all, AI is just software, isn’t it?) and the good guidance that is already available from different sources. So what can possibly go wrong?
Regulatory pressure in the EU (CRA, NIS-2 and the AI Act)
Throughout 2025, regulatory momentum continued to build, particularly within the EU. The NIS-2 Directive, in effect since 2024, introduced stricter cybersecurity governance requirements for essential sectors finally also in Germany, while the Cyber Resilience Act (CRA) set out baseline security expectations for digital products. NIS2 targets a significant number of organizations in EU and Germany deemed relevant in terms of size or sector (plus special ‚essential‘ cases). The CRA is a product regulation that will have a severe impact on a wide range of products with digital elements on the EU market, including IoT devices, desktop and mobile apps. It will also affect open-source projects with a commercial background, although „pure“““ open-source projects remain exempt. Meanwhile, the EU AI Act, which is set to come into full effect in 2026, will impose significant obligations on providers and deployers of high-risk AI systems (and transparency obligations on others). Application and product security are central to all of these regulations. They can be used as business cases to advocate for better application security, but AppSec teams also need to take compliance with these regulations on their roadmap.
Open-source supply chain issues are nothing new, but the sophistication of the impact and maturity of the attacks are increasing. Automated, AI-driven attacks, such as Shai Hulud, provide an indication of what might be to come. By November 2025, Shai-Hulud 2.0 had compromised 796 NPM packages (with over 20 million weekly downloads) in order to steal credentials from developers and CI/CD environments. Shortly afterwards, a critical vulnerability in the React framework, dubbed ‚React2Shell‚ was exploited on a large scale by both opportunistic cybercriminals and state-linked espionage groups within days of its disclosure. Although the adoption of SBOMs and improved dependency controls has increased and tools are readily available, the overall threat level remains high. As an industry, we have started to adopt processes and tools to mitigate the increased risks, but we are far from having them under control.
Developer Velocity vs. Security Debt (or: Vibe Coding)
In 2025, AI tools are used daily by nearly 50% of developer to increase productivity (- maybe not in every scenario, and with a bit of decreasing confidence in the tools). The definition of ‚developer productivity‘ remains vague but AI now generates 41% of code or even more. Vibe coding, whereby developers use AI prompts to iterate code until something functional emerges, becomes more common. However, this workflow often prioritises functionality over security, leading to vulnerabilities or insecure defaults being introduced. The number of CVEs surpassed 48,000 in 2025, a 20% increase from the year before, indicating that software security quality remains a systemic challenge. Developers may accept code suggestions without fully understanding them, resulting in inadequate oversight of the actual functionality of the code and a ‚shaky foundations‘, as even Cursor’s CEO warned. Therefore, despite AI being deployed for vulnerability detection and automated code fixes (potentially introducing new issues), developer training and the establishment of a sustainable security culture remain essential (excluding, perhaps, phishing training). In terms of development culture, security should enable, rather than control, but it must keep up with the increased development speed through scaling, automation, and prioritization.
AI changing both attack and defense
AI continues to be integrated into security processes. Workflow automation tools are entering the security space, but AppSec SOAR and ASPM has yet to be established. AI oriented use cases such as automatic fixes for vulnerabilities, ticket enrichment and AI-supported vulnerability triage, as well as support for manual processes such as threat modelling, are continuously being explored. AI-assisted systems aim to help teams prioritize vulnerabilities based on real exploit risk, correlate code and runtime data for richer context and filter out false positives to reduce alert fatigue. However, AI assisted software vulnerability management tools that live up to the high expectations have not yet fully arrived. Automated penetration testing tools are improving, but attackers are also using AI as a weapon. More sophisticated phishing campaigns continue to erode user trust and prompt changes to IAM mechanisms (MFA, of course, and Passkeys). Threat actors have weaponized AI to scale up their campaigns, using generative AI to automate malware development, produce convincing phishing lures and generate increasingly convincing deepfake content for social engineering attacks. This ‚AI augmentation‘ of attacks enables even less-skilled adversaries to carry out sophisticated operations by letting AI handle the heavy lifting, from writing exploit code to solving problems on the fly. The time it takes attackers to exploit vulnerabilities before patches are available has shortened once again, falling into the negative at -1 day.
So, amidst all these slightly unpredictable and rapidly changing events, what’s next? I suppose, it will be a continuation and intensification of what we’ve already seen. Organizations have to manage ever-growing volumes of security-relevant data, including architectural diagrams, threat models, cloud configurations, runtime telemetry, compliance artifacts and AI outputs. At the same time, AI is beginning to actively and independently steer processes, even though we do not yet fully understand the risks involved. Opportunity lies in integrating knowledge silos more effectively to provide a clearer view and analysis of relevant risks to focus on. The common thread — and threat — is, however, complexity: in terms of technology, regulation and adversaries. We must all navigate an environment in which complex, rapidly changing architectures and technologies require constant attention. We must avoid failure while moving forward at an ever-increasing speed. Let’s work together to maintain balance and stay in control.

von Benjamin Altmiks | Feb. 18, 2025 | Cyber-Sicherheit, Machine Learning and AI, News
ChatGPT hat sich längst in den Arbeitsalltag eines Großteils der Computer-nutzenden Bevölkerung integriert – und das weit über die Tech-Branche hinaus. Doch trotz des Erfolgs bleiben zentrale Kritikpunkte bestehen, allen voran der enorme Ressourcenverbrauch.
Die Neue Zürcher Zeitung berichtet, dass eine einzelne ChatGPT-Anfrage bis zu 30-mal mehr Strom verbraucht als eine Google-Suche.
Ein neues Sprachmodell, das dank effizienterer Berechnungen weniger Chips benötigt und dadurch den Energieverbrauch senkt, wäre daher zweifellos ein bedeutender Fortschritt. Die Argumentation hinter DeepSeek stützt sich genau darauf: eine ressourcenschonendere Algorithmenbasis als rein technische Verbesserung.
Doch was, wenn dieser vermeintliche Durchbruch gar nicht so innovativ ist – sondern größtenteils nur abgeschaut oder gar kopiert wurde?
Genau dieser Verdacht steht nun im Raum – erhoben von OpenAI selbst. Wie die Financial Times berichtet, behauptet das Unternehmen, Beweise dafür zu haben, dass Chinas DeepSeek sein Modell genutzt hat, um einen eigenen KI-Wettbewerber zu trainieren.
Doch was genau bedeutet das? Der Vorwurf dreht sich um Model Theft – also den Diebstahl eines bereits trainierten Machine-Learning-Modells. Diese Bedrohung ist nicht neu: Bereits 2023 stufte OWASP sie sowohl unter die Top 10 Risiken für Large Language Models (LLMs) als auch unter die Top 10 allgemeinen Machine-Learning-Risiken ein.
Die Methode dahinter ist ebenso simpel wie effektiv: Eine enorme Anzahl gezielter Anfragen wird an ein bestehendes Modell gesendet – in diesem Fall ChatGPT. Die generierten Antworten dienen dann als Trainingsdaten für ein neues Modell, das auf diesem Wissen aufbaut. So soll DeepSeek sich einen entscheidenden Vorteil verschafft haben – wie die folgende Grafik veranschaulicht:
Die folgende Abbildung basiert auf Tramèr et al. (2016), wurde jedoch angepasst und erweitert.
In der dargestellten Grafik wird OpenAI als Data Owner bezeichnet, obwohl ChatGPT größtenteils auf öffentlich zugänglichen Daten trainiert wurde. Dies wirft eine grundlegende ethische Frage auf: Sollten Ergebnisse, die aus öffentlichen Daten generiert wurden, nicht ebenfalls frei verfügbar und für die Allgemeinheit nutzbar sein? Gleichzeitig darf jedoch nicht außer Acht gelassen werden, dass OpenAI erhebliche Ressourcen – sowohl in Form der Datenaufbereitung und Klassifizierung als auch finanzieller Investitionen – in die Entwicklung des Modells gesteckt hat. Diese Arbeit muss geschützt werden, weshalb es nicht ohne Weiteres akzeptabel wäre, wenn DeepSeek ein Modell veröffentlicht, das auf ChatGPT basiert.
Welche Daten DeepSeek letztendlich für das Training verwendet hat, weiß jedoch nur das Unternehmen selbst. Unabhängig davon bleibt der technische Ansatz sowohl beeindruckend als auch beunruhigend. Selbst wenn das Modell lediglich eine gelungene Nachbildung von ChatGPT sein sollte, stellt dies einen beachtlichen technologischen Fortschritt dar – schließlich ist es bislang keinem anderen Unternehmen gelungen, auf dieser Basis ein konkurrenzfähiges Modell in vergleichbarer Qualität zu entwickeln.
Für Unternehmen, die eigene Sprachmodelle mit firmeninternen Daten trainieren, wird in Zukunft erhöhte Vorsicht geboten. Denn auch diese Modelle könnten potenziell kopiert und in anderen Unternehmen zweckentfremdet werden. Ob es sich um Microsoft handelt, dessen Marktstrategie besser vorhergesagt werden soll, oder um ein mittelständisches Unternehmen, dessen interne Prozesse und strategische Entscheidungen durch solche Modelle rekonstruiert werden könnten – Sprachmodelle müssen als wertvolle Assets betrachtet und entsprechend geschützt werden.
Wie sich Sprachmodelle und andere Machine-Learning-Systeme strategisch und langfristig absichern lassen, zeigen wir Ihnen bei secureIO. Buchen Sie jetzt ein Webinar, einen Vortrag oder eine praxisnahe Schulung direkt in Ihrem Unternehmen.
Quellen & weiterführende Informationen



