AI Security Landscape
Von Benjamin Altmiks
KI in der Security: Die Frage ist nicht ob, sondern wo man anfängt
Wer ein altes Haus energetisch sanieren will, steht schnell vor einer entscheidenden Frage: Wo fängt man eigentlich an? Tauscht man zuerst die alte Ölheizung gegen eine Wärmepumpe? Oder lässt man besser erst eine Photovoltaikanlage aufs Dach bauen, die den Strom für ebenjene Wärmepumpe liefert? Beides ergibt Sinn, aber welcher der richtige erste Schritt ist, lässt sich ohne entsprechende Expertise oft nur schwer beurteilen.
Bei großen und mittelständischen Unternehmen sieht es gerade sehr ähnlich aus. KI? Ja gerne. Aber wo beginnen? Genau diese Unsicherheit beobachte ich seit längerem auch im Security-Bereich. Der naheliegende Einstieg ist meist ein vertrautes, alltägliches Thema. Viele lassen sich von einer KI zum Beispiel einfach lange Logfiles oder Reports zusammenfassen und auswerten. Und wenn ich der KI ohnehin schon solche Berichte vorlege, warum reiche ich ihr dann nicht gleich mehr Material, etwa den Source Code oder die Netzwerkinfrastruktur, und lasse beides direkt mitprüfen?
Schwierig ist dabei selten die Frage, ob KI hilft. Schwierig ist die Frage, wo man anfängt, ohne sich zu verzetteln.
Eine Karte, um sich zu orientieren
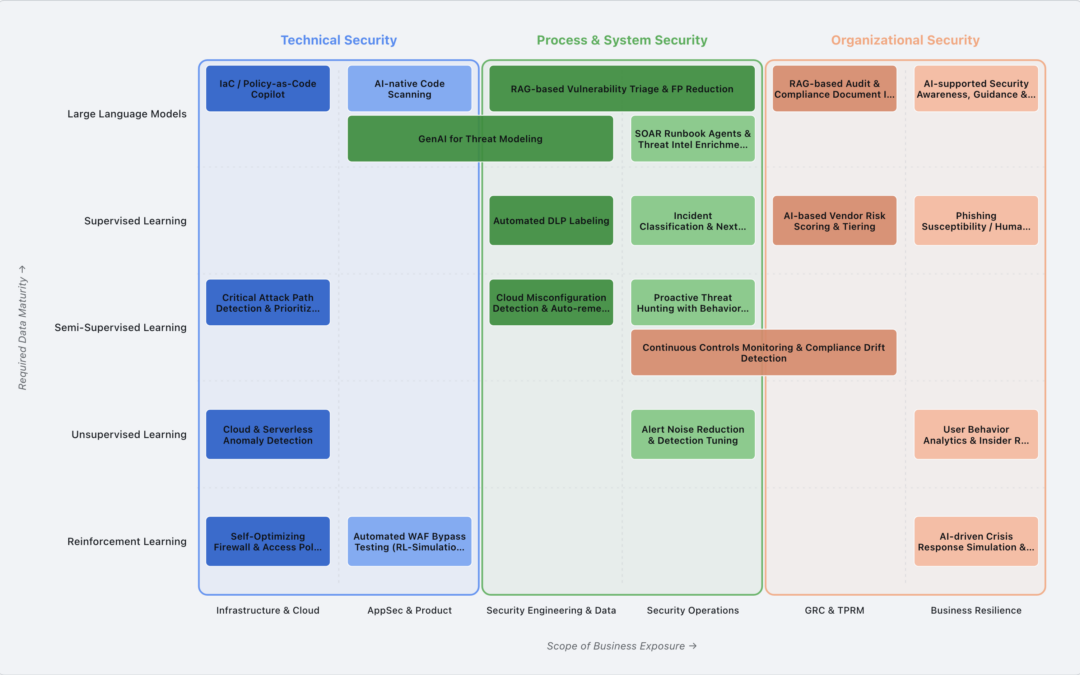
Aus genau diesem Grund haben wir den AI Security Landscape gebaut: eine offene Übersicht, die konkrete KI-Anwendungsfälle in der Cyber Security sortiert. Auf der einen Achse stehen die Security-Abteilungen, von Infrastruktur und AppSec über Security Operations bis hin zu GRC und Business Resilience. Auf der anderen Achse steht der jeweils passende Machine-Learning-Ansatz, von unüberwachtem Lernen bis zu Large Language Models.
Der wichtigste Gedanke dahinter: Ein LLM ist nicht immer die beste Wahl. Für viele Aufgaben passt ein klassischer ML-Ansatz schlicht besser, ist robuster und braucht weniger Aufsicht. Die Karte macht das sichtbar und hilft Teams zu erkennen, welcher Einstieg zu ihrer Datenlage und ihrem Reifegrad passt.

Ein Beispiel: der Weg zur KI-gestützten Code-Analyse
Nehmen wir ein Unternehmen, das künftig seine Code-Analysen von KI unterstützen lassen möchte. Dass LLMs dazu in der Lage sind, wurde zuletzt eindrucksvoll sichtbar, als ein Modell einen Bug in kritischer Software fand, der zuvor 27 Jahre lang von Sicherheitsexperten unentdeckt geblieben war. Im Alltag der Softwareentwicklung können LLMs auf dieselbe Weise Qualität und Sicherheit spürbar verbessern.
Nur: Ein LLM ohne Zusatzinformationen einfach blind über den Code laufen zu lassen, ist selten der beste Ansatz. Genau hier setzt der AI Security Landscape an. Er zeigt, dass ein vorgelagertes Threat Modeling dem Scanner wertvollen Kontext liefert. Welche Komponenten und Klassen sind besonders kritisch? Wie hängen die Teile zusammen? Mit diesen Antworten weiß die KI, worauf sie zuerst schauen muss, statt flach über die gesamte Codebasis zu scannen.
Das Schöne daran: Auch das Threat Modeling selbst lässt sich von KI vorbereiten. Wie mithilfe des Model Context Protocol (MCP) künftig automatisiert Threat Models erstellt werden können, ist ebenfalls Teil des AI Security Landscape. Damit wird ein KI-gestütztes Threat Modeling oft zum besseren Startpunkt für die erste KI-Umsetzung im Unternehmen, weil es allen folgenden Schritten eine solide Grundlage gibt.

Wenn die Grundlagen schon stehen
Und wenn ein Unternehmen bereits erfolgreich Threat Modeling betreibt und darauf aufbauend ein LLM zur Schwachstellen-Identifikation im Source Code nutzt? Dann hört der AI Security Landscape nicht auf. Er zeigt, welche Ansätze sich parallel oder anschließend lohnen.
Ein gutes Beispiel ist die RAG-based Vulnerability Triage & FP Reduction. Hier laufen die verschiedenen Informationsquellen zusammen, das Threat Model, die Scan-Ergebnisse und ergänzende Kontexte wie Architekturbeschreibungen. Sie werden strukturiert in eine Vektordatenbank überführt, also eine Art zentrale Wissensplattform, auf die ein LLM gezielt zugreifen kann. Auf dieser Basis lässt sich jede gefundene Schwachstelle fundiert bewerten. Das Modell kann mit dem vollen Kontext deutlich verlässlicher einschätzen, was ein echter Befund ist, was vermutlich ein False Positive bleibt und ob eine Schwachstelle überhaupt erreichbar ist.
Aus einem einzelnen Werkzeug wird so Schritt für Schritt eine zusammenhängende Kette, in der jeder Baustein den nächsten besser macht. Genau das ist der Gedanke hinter der Karte: nicht überall gleichzeitig anfangen, sondern dort, wo der erste Schritt den größten Hebel für alle weiteren hat.
Mitmachen erwünscht
Der AI Security Landscape ist ein offenes Projekt. Er lebt davon, dass Praktikerinnen und Praktiker ihre Erfahrungen einbringen, neue Use Cases ergänzen und bestehende schärfen. Wer einen Anwendungsfall vermisst oder aus der eigenen Praxis etwas beitragen kann, ist herzlich eingeladen, mitzuwirken.
- Zur interaktiven Karte: https://secureio-gmbh.github.io/ai-security-landscape/
- Zum offenen Repository: https://github.com/secureIO-GmbH/ai-security-landscape
Einen Topic beizutragen ist bewusst einfach gehalten: eine Markdown-Datei kopieren, ausfüllen, Pull Request öffnen. Den Rest prüft die Pipeline automatisch. Jeder Beitrag macht die Karte ein Stück nützlicher für alle, die gerade vor derselben Frage stehen: KI in der Security, ja gerne, aber wo anfangen?


